Keeping PACE with GPU enabled compute to detect global cloud cover using satellite data


PACE is the NASA Plankton, Aerosol, Cloud, ocean Ecosystem mission that focuses on understanding ocean health and its impact on the atmosphere. Together with the Ocean Carbon and Biochemistry (OCB) program, a one-week hackathon ran from Aug 4 to Aug 8 on the 2i2c-hosted CryoCloud hub. The goal of the hackathon was to explore new Earth science data streams provided by the OCI , SPEXone and HARP2 instruments using Python.
Machine Learning with GPUs #
One of the most advanced tutorials delivered during the hackathon was the Machine Learning Tutorial . The tutorial focused on creating a machine learning pipeline to detect cloud cover from satellite imagery. This was done by training a convolutional neural network (CNN) to assign each pixel a binary value to indicate whether the location was covered by cloud or not. To improve the spatial context beyond a single pixel value, as the likelihood of a pixel containing cloud cover increases if its neighbours also contain cloud cover, the CNN needs to be trained on the entire image at once rather than at a single pixel level. This massively increases the training time, but also allows the CNN to learn more complex relationships between pixels.
GPUs have a far greater number of cores than CPUs that are well-suited for accelerating the massive parallel processing needed to train a neural network on the large amounts of image data in the above scenario. PyTorch is a popular Python library for training CNNs, available for both CPUs and GPUs, and is an ideal tool for performing this kind of work. In terms of the accelerator hardware available on the CryoCloud hub, 2i2c provisions an instance with an NVIDIA Tesla T4 GPU with 4 CPUS, 16GB of RAM and 2,560 CUDA cores.
Managing shared memory on 2i2c hubs #
PyTorch uses shared memory to share data for parallel processing. The shared memory is provided by /dev/shm, a temporary file store mount that can access the RAM available on an instance. Accessing data stored in RAM is significantly faster than from disk storage (i.e. /tmp), making /dev/shm a good choice for training large neural networks.
While developing the above tutorial, tutorial lead Sean Foley (NASA/GSFC/SED & Morgan State University & GESTAR II) noticed that the shared memory segment size was 64 MB set by default on the container, separate from the total 16 GB RAM that was available on the host.
You can check the amount of shared memory available on your hub in a terminal with the command
df -h | grep shm
As you might expect, 64 MB of shared memory is not enough for training over 160,000 images in the tutorial. 2i2c was able to increase the limit to 8 GB for all users on the CryoCloud hub within an hour of the issue being reported and we upstreamed the change for all 2i2c hubs (see GitHub pull requests for CryoCloud and all 2i2c hubs ).
Conclusion #
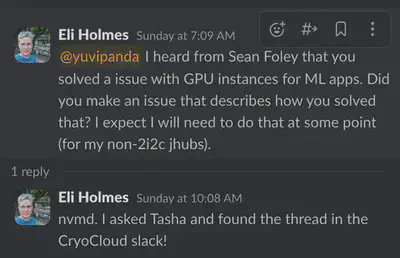
This event demonstrates the economy of how running shared and open infrastructure dynamically solves problems for the benefit of many users, not just for one occasion. Learning experiences such as the above are transferred and embedded upstream into transparent and flexible open source software that impacts not only all users of 2i2c operated hubs, but also generalized for the wider research community at large (case in point, see the Slack thread below from Eli Holmes , operator of the NOAA Fisheries hubs)! We are grateful for the strong partnerships with our communities who help us to co-design impactful solutions that are specific for their needs and accessible to all.
References and Acknowledgments #
- Sean Foley (NASA/GSFC/SED & Morgan State University & GESTAR II)
- Tasha Snow (ESSIC UMD & NASA GSFC & CryoCloud )
- PACE Hackweek Jupyter Book